面向开发者的 Prompt 工程
LLM 分类

随着 LLM 的发展,其大致可以分为两种类型,后续称为基础 LLM(Base LLM) 和指令微调(Instruction Tuned)LLM。基础 LLM 是基于文本训练数据,训练出预测下一个单词能力的模型。其通常通过在互联网和其他来源的大量数据上训练,来确定紧接着出现的最可能的词。例如,如果你以“从前,有一只独角兽”作为 Prompt ,基础 LLM 可能会继续预测“她与独角兽朋友共同生活在一片神奇森林中”。但是,如果你以“法国的首都是什么”为 Prompt ,则基础 LLM 可能会根据互联网上的文章,将回答预测为“法国最大的城市是什么?法国的人口是多少?”,因为互联网上的文章很可能是有关法国国家的问答题目列表。
与基础语言模型不同,指令微调 LLM 通过专门的训练,可以更好地理解并遵循指令。举个例子,当询问“法国的首都是什么?”时,这类模型很可能直接回答“法国的首都是巴黎”。指令微调 LLM 的训练通常基于��预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。有时还会采用 RLHF(reinforcement learning from human feedback,人类反馈强化学习)技术,根据人类对模型输出的反馈进一步增强模型遵循指令的能力。通过这种受控的训练过程。指令微调 LLM 可以生成对指令高度敏感、更安全可靠的输出,较少无关和损害性内容。因此。许多实际应用已经转向使用这类大语言模型。
Prompt 原则
编写 Prompt 有两个原则:编写清晰、具体的指令和给予模型充足思考时间:
-
清晰具体的指令是指:我们要清晰明确的表达我们的需求,提供充足的上下文,让 LLM 理解我们的意图。
-
给予模型充足的思考时间是指:在 Prompt 中添加逐步推理的要求,能让语言模型投入更多时间逻辑思维,输出结果也将更可靠准确。
使用分隔符清晰地表示输入的不同部分
可以使用以下分隔符:
"""```---< ><tag></tag>
使用分隔符可以将指令,上下文和输入分开,避免混�淆。
示例
text = f"""
您应该提供尽可能清晰、具体的指示,以表达您希望模型执行的任务。\
这将引导模型朝向所需的输出,并降低收到无关或不正确响应的可能性。\
不要将写清晰的提示词与写简短的提示词混淆。\
在许多情况下,更长的提示词可以为模型提供更多的清晰度和上下文信息,从而导致更详细和相关的输出。
"""
# 需要总结的文本内容
prompt = f"""
把用三个反引号括起来的文本总结成一句话。
```{text}```
"""
# 指令内容,使用 ``` 来分隔指令和待总结的内容
response = get_completion(prompt)
print(response)
为了获得所需的输出,您应该提供清晰、具体的指示,避免与简短的提示词混淆,并使用更长的提示词来提供更多的清晰度和上下文信息。
使用分隔符还有一个好处就是避免 提示词注入 (Prompt Rejection)。简单来说就是输入中包含指令。
Prompt Rejection 示例

要求结构化的输出
结构化的输出方便我们后续的处理。
示例
prompt = f"""
请生成包括书名、作者和类别的三本虚构的、非真实存在的中文书籍清单,\
并以 JSON 格式提供,其中包含以下键:book_id、title、author、genre。
"""
response = get_completion(prompt)
print(response)
[
{
"book_id": 1,
"title": "月亮与六便士",
"author": "毛姆",
"genre": "文学"
},
{
"book_id": 2,
"title": "白鹿原",
"author": "陈忠实",
"genre": "文学"
},
{
"book_id": 3,
"title": "平凡的世界",
"author": "路遥",
"genre": "文学"
}
]
要求模型检查是否满足条件
如果输入不一定能满足任务的前置条件,我们可以让模型先检查这些条件,如果不满足,停止执行或者做一些其他的处理。
示例
# 满足条件的输入(text中提供了步骤)
text_1 = f"""
泡一杯茶很容易。首先,需要把水烧开。\
在等待期间,拿一个杯子并把茶包放进去。\
一旦水足够热,就把它倒在茶包上。\
等待一会儿,让茶叶浸泡。几分钟后,取出茶包。\
如果您愿意,可以加一些糖或牛奶调味。\
就这样,您可以享受一杯美味的茶了。
"""
prompt = f"""
您将获得由三个引号括起来的文本。\
如果它包含一系列的指令,则需要按照以下格式重新编写这些指令:
第一步 - ...
第二步 - …
…
第N步 - …
如果文本中不包含一系列的指令,则直接写“未提供步骤”。"
\"\"\"{text_1}\"\"\"
"""
response = get_completion(prompt)
print("Text 1 的总结:")
print(response)
Text 1 的总结:
第一步 - 把水烧开。
第二步 - 拿一个杯子并把茶包放进去。
第三步 - 把烧开的水倒在茶包上。
第四步 - 等待几分钟,让茶叶浸泡。
第五步 - 取出茶包。
第六步 - 如果需要,加入糖或牛奶调味。
第七步 - 就这样,您可以享受一杯美味的茶了。
# 不满足条件的输入(text中未提供预期指令)
text_2 = f"""
今天阳光明媚,鸟儿在歌唱。\
这是一个去公园散步的美好日子。\
鲜花盛开,树枝在微风中轻轻摇曳。\
人们外出享受着这美好的��天气,有些人在野餐,有些人在玩游戏或者在草地上放松。\
这是一个完美的日子,可以在户外度过并欣赏大自然的美景。
"""
prompt = f"""
您将获得由三个引号括起来的文本。\
如果它包含一系列的指令,则需要按照以下格式重新编写这些指令:
第一步 - ...
第二步 - …
…
第N步 - …
如果文本中不包含一系列的指令,则直接写“未提供步骤”。"
\"\"\"{text_2}\"\"\"
"""
response = get_completion(prompt)
print("Text 2 的总结:")
print(response)
Text 2 的总结:
未提供步骤。
提供少量示例
Few-shot prompting,即在要求模型执行实际任务之前,给模型一两个已完成的样例,让模型了解我们的要求和期望的输出样式。
示例
prompt = f"""
您的任务是以一致的风格回答问题。
<孩子>: ��请教我何为耐心。
<祖父母>: 挖出最深峡谷的河流源于一处不起眼的泉眼;最宏伟的交响乐从单一的音符开始;最复杂的挂毯以一根孤独的线开始编织。
<孩子>: 请教我何为韧性。
"""
response = get_completion(prompt)
print(response)
<祖父母>: 韧性是一种坚持不懈的品质,就像一棵顽强的树在风雨中屹立不倒。它是面对困难和挑战时不屈不挠的精神,能够适应变化和克服逆境。韧性是一种内在的力量,让我们能够坚持追求目标,即使面临困难和挫折也能坚持不懈地努力。
指定完成任务所需的步骤
接下来我们将通过给定一个复杂任务,给出完成该任务的一系列步骤,来展示这一策略的效果。
首先我们描述了杰克和吉尔的故事,并给出提示词执行以下操作:首先,用一句话概括三个反引号限定的文本。第二,将摘要翻译成英语。第三,在英语摘要中列出每个名称。第四,输出包含以下键的 JSON 对象:英语摘要和人名个数。要求输出以换行符分隔。
示例
text = f"""
在一个迷人的村庄里,兄妹杰克和吉尔出发去一个山顶井里打水。\
他们一边唱着欢乐的歌,一边往上爬,\
然而不幸降临——杰克绊了一块石头,从山上滚了下来,吉尔紧随其后。\
虽然略有些摔伤,但他们还是回到了温馨的家中。\
尽管出了这样的意外,他们的冒险精神依然没有减弱,继续充满愉悦地探索。
"""
# example 1
prompt_1 = f"""
执行以下操作:
1-用一句话概括下面用三个反引号括起来的文本。
2-将摘要翻译成英语。
3-在英语摘要中列出每个人名。
4-输出一个 JSON 对象,其中包含以下键:english_summary,num_names。
请用换行符分隔您的答案。
Text:
```{text}```
"""
response = get_completion(prompt_1)
print("prompt 1:")
print(response)
prompt 1:
1-两个兄妹在山�上打水时发生意外,但最终平安回家。
2-In a charming village, siblings Jack and Jill set off to fetch water from a well on top of a hill. While singing joyfully, they climbed up, but unfortunately, Jack tripped on a stone and rolled down the hill, with Jill following closely behind. Despite some minor injuries, they made it back to their cozy home. Despite the mishap, their adventurous spirit remained undiminished as they continued to explore with delight.
3-Jack, Jill
4-{"english_summary": "In a charming village, siblings Jack and Jill set off to fetch water from a well on top of a hill. While singing joyfully, they climbed up, but unfortunately, Jack tripped on a stone and rolled down the hill, with Jill following closely behind. Despite some minor injuries, they made it back to their cozy home. Despite the mishap, their adventurous spirit remained undiminished as they continued to explore with delight.", "num_names": 2}
上述输出仍然存在一定问题,例如,键“姓名”会被替换为法语(译注:在英文原版中,要求从英语翻译到法语,对应指令第三步的输出为 'Noms:',为 Name 的法语,这种行为难以预测,并可能为导出带来困难)
因此,我们将 Prompt 加以改进,该 Prompt 前半部分不变,同时确切指定了输出的格式。
示例
prompt_2 = f"""
1-用一句话概括下面用<>括起来的文本。
2-将摘要翻译成英语。
3-在英语摘要中列出每个名称。
4-输出一个 JSON 对象,其中包含以下键:English_summary,num_names。
请使用以下格式:
文本:<要总结的文本>
摘要:<摘要>
翻译:<摘要的翻译>
名称:<英语摘要中的名称列表>
输出 JSON:<带有 English_summary 和 num_names 的 JSON>
Text: <{text}>
"""
response = get_completion(prompt_2)
print("\nprompt 2:")
print(response)
prompt 2:
Summary: 在一个迷人的村庄里,兄妹杰克和吉尔在山顶井里打水时发生了意外,但他们的冒险精神依然没有减弱,继续充满愉悦地探索。
Translation: In a charming village, siblings Jack and Jill set off to fetch water from a well on top of a hill. Unfortunately, Jack tripped on a rock and tumbled down the hill, with Jill following closely behind. Despite some minor injuries, they made it back home safely. Despite the mishap, their adventurous spirit remained strong as they continued to explore joyfully.
Names: Jack, Jill
JSON Output: {"English_summary": "In a charming village, siblings Jack and Jill set off to fetch water from a well on top of a hill. Unfortunately, Jack tripped on a rock and tumbled down the hill, with Jill following closely behind. Despite some minor injuries, they made it back home safely. Despite the mishap, their adventurous spirit remained strong as they continued to explore joyfully.", "num_names": 2}
指导模型在下结论之前找出一个自己的解法
在设计 Prompt 时,我们还可以通过明确指导语言模型进行自主思考,来获得更好的效果。
举个例子,假设我们要语言模型判断一个数学问题的解答是否正确。仅仅提供问题和解答是不够的,语言模型可能会匆忙做出错误判断。
相反,我们可以在 Prompt 中先要求语言模型自己尝试解决这个问题,思考出自己的解法,然后再与提供的解答进行对比,判断正确性。这种先让语言模型自主思考的方式,能帮助它更深入理解问题,做出更准确的判断。
接下来我们会给出一个问题和一份来自学生的解答,要求模型判断解答是否正确:
示例
prompt = f"""
判断学生的解决方案是否正确。
问题:
我正在建造一个太阳能发电站,需要帮助计算财务。
土地费用为 100美元/平方英尺
我可以以 250美元/平方英尺的价格购买太阳能电池板
我已经谈判好了维护合同,每年需要支付固定的10万美元,并额外支付每平方英尺10美元
作为平方英尺数�的函数,首年运营的总费用是多少。
学生的解决方案:
设x为发电站的大小,单位为平方英尺。
费用:
土地费用:100x
太阳能电池板费用:250x
维护费用:100,000美元+100x
总费用:100x+250x+100,000美元+100x=450x+100,000美元
"""
response = get_completion(prompt)
print(response)
学生的解决方案是正确的。他正确地计算了土地费用、太阳能电池板费用和维护费用,并将它们相加得到了总费用。
但是注意,学生的解决方案实际上是错误的。(维护费用项 100x 应为 10x,总费用 450x 应为 360x)
我们可以通过指导模型先自行找出一个解法来解决这个问题。
在接下来这个 Prompt 中,我们要求模型先自行解决这个问题,再根据自己的解法与学生的解法进行对比,从而判断学生的解法是否正确。同时,我们给定了输出的格式要求。通过拆分任务、明确步骤,让模型有更多时间思考,有时可以获得更准确的结果。在这个例子中,学生的答案是错误的,但如果我们没有先让模型自己计算,那么可能会被误导以为学生是正确的。
示例
prompt = f"""
请判断学生的解决方案是否正确,请通过如下步骤解决这个问题:
步骤:
首先,自己解决问题。
然后将您的解决方案与学生的解决方案进行比较,对比计算得到的总费用与学生计算的总费用是否一致,并评估学生的解决方案是否正确。
在自己完成问题之前,请勿决定学生的解决方案是否正确。
使用以下格式:
问题:问题文本
学生的解决方案:学生的解决方案文本
实际解决方案和步骤:实际解决方案和步骤文本
学生计算的总费用:学生计算得到的总费用
实际计算的总费用:实际计算出的总费用
学生计算的费用和实际计算的费用是否相同:是或否
学生的解决方案和实际解决方案是否相同:是或否
学生的成绩:正确或不正确
问题:
我正在建造一个太阳能发电站,需要帮助计�算财务。
- 土地费用为每平方英尺100美元
- 我可以以每平方英尺250美元的价格购买太阳能电池板
- 我已经谈判好了维护合同,每年需要支付固定的10万美元,并额外支付每平方英尺10美元;
作为平方英尺数的函数,首年运营的总费用是多少。
学生的解决方案:
设x为发电站的大小,单位为平方英尺。
费用:
1. 土地费用:100x美元
2. 太阳能电池板费用:250x美元
3. 维护费用:100,000+100x=10万美元+10x美元
总费用:100x美元+250x美元+10万美元+100x美元=450x+10万美元
实际解决方案和步骤:
"""
response = get_completion(prompt)
print(response)
实际解决方案和步骤:
1. 土地费用:每平方英尺100美元,所以总费用为100x美元。
2. 太阳能电池板费用:每平方英尺250美元,所以总费用为250x美元。
3. 维护费用:固定费用为10万美元,额外费用为每平方英尺10美元,所以总费用为10万美元+10x美元。
4. 总费用:将上述三项费用相加,得到总费用为100x美元+250x美元+10万美元+10x美元=360x+10万美元。
学生计算的总费用:450x+10万美元
实际计算的总费用:360x+10万美元
学生计算的费用和实际计算的费用是否相同:否
学生的解决方案和实际解决方案是否相同:否
学生的成绩:不正确
虚假信息
虚假知识:模型偶尔会生成一些看似真实实则编造的知识
在开发与应用语言模型时,需要注意它们可能生成虚假信息的风险。尽管模型经过大规模预训练,掌握了丰富知识,但它实际上并没有完全记住所见的信息,难以准确判断自己的知识边界,可能做出错误推断。若让语言模型描述一个不存在的产品,它可能会自行构�造出似是而非的细节。这被称为“幻觉”(Hallucination),是语言模型的一大缺陷。
Details
示例
如下示例展示了大模型的幻觉。我们要求告诉我们华为公司生产的 GT Watch 运动手表 产品的信息,事实上,这个公司是真实存在的,但产品是编造的,而模型一本正经地提供了它编造的知识,而且迷惑性很强。prompt = f"""
告诉我华为公司生产的GT Watch运动手表的相关信息
"""
response = get_completion(prompt)
print(response)
华为公司生产的GT Watch运动手表是一款智能手表,具有多种功能和特点。以下是相关信息:
1. 设计和外观:GT Watch采用圆形表盘设计,具有精致的外观和高质量的材料制造。它有多种颜色和表带选择,可以根据个人喜好进行定制。
2. 显示屏:GT Watch配备了1.39英寸的AMOLED显示屏,具有高清分辨率和良好的可视性。用户可以通过触摸屏幕进行操作和导航。
3. 运动追踪:GT Watch具有全天候的运动追踪功能,可以监测用户的步数、跑步距离、卡路里消耗和心率等数据。它还支持多种运动模式,如跑步、骑行、游泳等。
4. 健康监测:GT Watch可以监测用户的心率、血氧饱和度和睡眠质量等健康指标。它还提供健康建议和提醒,帮助用户保持良好的健康状态。
5. 通知和连接:GT Watch可以与用户的手机进行连接,通过蓝牙技术实现通知推送和电话提醒。用户可以在手表上查看短信、电话和社交媒体通知,无需拿出手机。
6. 长续航时间:GT Watch具有较长的续航时间,一次充电可以使用数天。它还支持快速充电技术,可以在短时间内充满电。
7. 其他功能:GT Watch还具有其他功能,如天气预报、闹钟、计时器、计步器等。它还支持NFC支付和音乐控制等便利功能。
总体而言,华为GT Watch是一款功能强大、外观精致的智能运动手表,适合那些注重健康和运动的用户使用。
限制输出的长度
可以在 prompt 中限制模型输出的长度,例如:use at most 100 words to summarize the following text。
但实际上模型的输出可能超过我们要求的长度,因为 llm 计算和判断文本长度依赖 tokennizer,一个 token 并不等于一个 word。
Temperature
大语言模型中的 “温度”(temperature) 参数可以控制生成文本的随机性和多样性。temperature 的值越大,语言模型输出��的多样性越大;temperature 的值越小,输出越倾向高概率的文本。
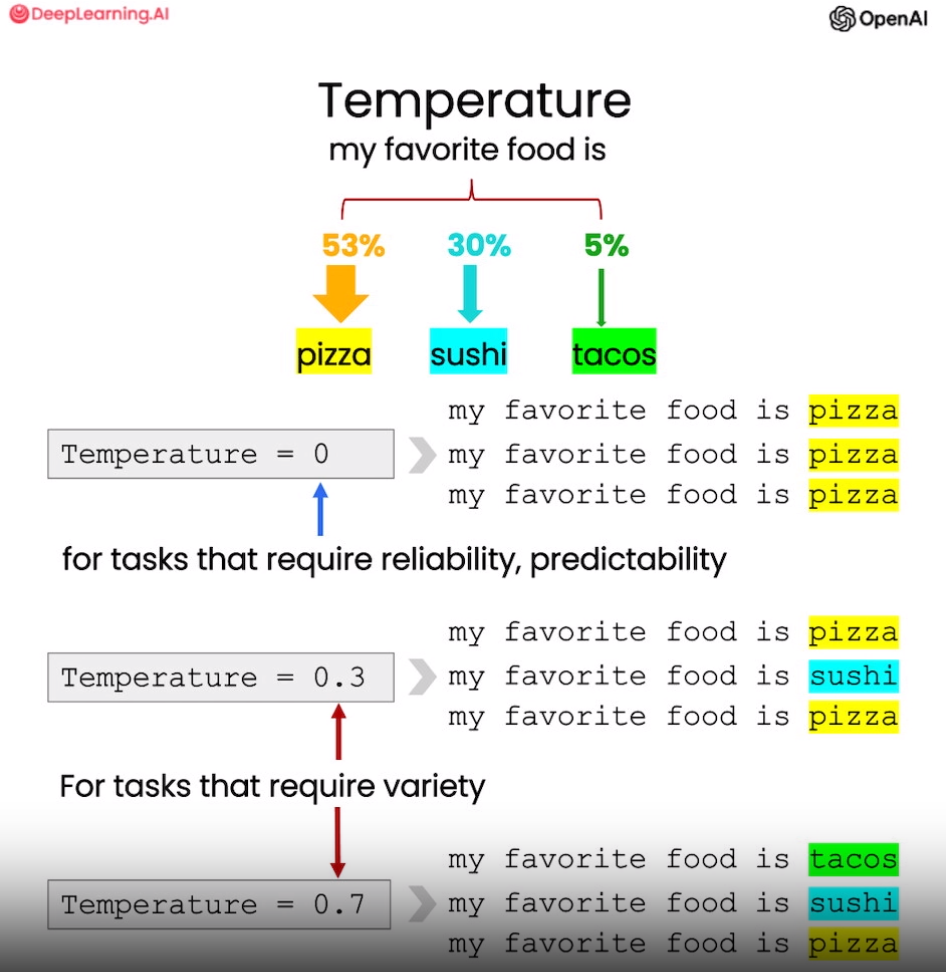
一般来说,如果需要可预测、可靠的输出,则将 temperature 设置为 0,这时如果使用相同的 prompt,得到的结果总是一样的。如果需要更具创造性的多样文本,那么适当提高 temperature 则很有帮助。调整这个参数可以灵活地控制语言模型的输出特性。
role
可以在 prompt 中指定模型的角色,从而方便的将上下文信息传递给模型。
messages = [
{'role':'system', 'content':'你是个友好的聊天机器人。'},
{'role':'user', 'content':'Hi, 我是Isa'},
{'role':'assistant', 'content': "Hi Isa! 很高兴认识你。今天有什么可以帮到你的吗?"},
{'role':'user', 'content':'是的,你可以提醒我, 我的名字是什么?'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)
# Output:
# 当然可以!您的名字是Isa。